
TL;DR: The margin of error gets smaller with the proportion: the given margin of error is most relevant the closer to 50% the support.
Warning: I am taking the polls to be of the form
Will you vote for party X: yes or no?
There is more than a little confusion about the margin of error in political polling amongst the Irish political commentators.
Polls frequently come with margins of error such as “3%” and if a small party polls less than this some people comment that the real support could be zero.
In this piece, I will present a new way of interpreting low poll numbers, show how it is derived, further explain where the approximate 3% figure comes from and show what the calculation should be for mid-ranking proportions.
The main point is that none of these margins of error are accurate for small proportions.
For those who don’t like the mathematics of it all I will explain in a softer way why polling at 1-2% is very unlikely when your true support is 0.5%.
The Correct Way to look at Low National Poll Results
Renua, Green Party, Social Democrat, Independent Alliance and AAA-PBP peeps… consider a random sample of 1000 voters taken from the electorate…
‘Soft’ Explanation of Why the Margin of Error is Small
Let me explain using smaller numbers why polling at 1-3% is very unlikely to put your true support at say 0.5%. Imagine a chain of ten niteclubs across Dublin with 100 people in each of them. Suppose that each of these 1000 people give their number when they arrive into the club and are entered into a text competition. Suppose that the chain texts a small number of customers to tell them that they have won a prize that they collect if they go up to the DJ.
Can you tell how many prizes there are just by going by what happens in one club?
The clubs with no winners can’t really say anything. Anything from 0-7 prizes overall seems quite likely: they might even think there is only 1 or 3 prizes because of that is ‘usually the way’.
The clubs with one winner probably think they are average — maybe there is a prize for every club and so 10 prizes in total.
However if a club gets two winners they probably don’t see themselves as special either and estimate that there could be 10-30 prizes overall if they are getting two.
What if I told you there were only five prizes? Could any club predict that accurately? How likely do you think that there were two prizes in one club of ten if there were only five prizes? Was this not a strange and unlikely outcome?
What if the numbers are bigger? 100 superclubs across Europe with 1000 people in each of them them. Imagine 500 prizes across the 100 superclubs: an average of only 5 a club? How likely do you think that in one of the superclubs that not 5, not 10, not 15 but 20 prizes were won?! When the numbers were chosen at random?
A poll result of 2% when the true support in the country is 0.5% is even more unlikely.
In fact the biggest problem with polling as done by market research companies in Ireland is that it isn’t remotely random nor representative. That is softer stuff: I have waited long enough before going into the sums!
The Maths for National Polls
Let 


is the proportion of voters for the particular party. We estimate 


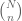

The random variable 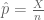
If 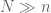

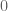
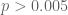
Now the probability of finding 
![\mathbb{P}[X=k]={n\choose k}p^k(1-p)^{n-k}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%5BX%3Dk%5D%3D%7Bn%5Cchoose+k%7Dp%5Ek%281-p%29%5E%7Bn-k%7D&bg=ffffff&fg=545454&s=0&c=20201002)
Suppose now that 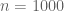



![\displaystyle \mathbb{P}[\hat{p}\in [0.005,0.015)\,|\,p=0.005]=\sum_{k=5}^{14}{1000\choose k}(0.005)^k(0.995)^{1000-k},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%5Chat%7Bp%7D%5Cin+%5B0.005%2C0.015%29%5C%2C%7C%5C%2Cp%3D0.005%5D%3D%5Csum_%7Bk%3D5%7D%5E%7B14%7D%7B1000%5Cchoose+k%7D%280.005%29%5Ek%280.995%29%5E%7B1000-k%7D%2C&bg=ffffff&fg=545454&s=0&c=20201002)
and is equal to 0.56=56%
We can calculate a number of these probabilities:
![\displaystyle \mathbb{P}[\text{polling at }\hat{p}\,|\,\text{true proportion is }p]=\sum_{k=1000\hat{p}-4}^{1000\hat{p}+5}{1000\choose k}p^k(1-p)^{n-k},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%5Ctext%7Bpolling+at+%7D%5Chat%7Bp%7D%5C%2C%7C%5C%2C%5Ctext%7Btrue+proportion+is+%7Dp%5D%3D%5Csum_%7Bk%3D1000%5Chat%7Bp%7D-4%7D%5E%7B1000%5Chat%7Bp%7D%2B5%7D%7B1000%5Cchoose+k%7Dp%5Ek%281-p%29%5E%7Bn-k%7D%2C&bg=ffffff&fg=545454&s=0&c=20201002)
indeed I have them summarised here:
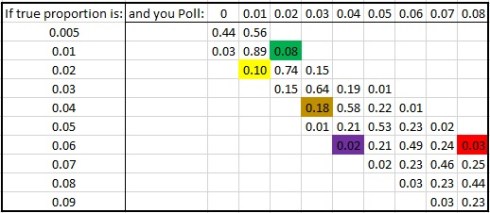
I have added in some of the poll results of smaller parties here to help you interpret this table.
- Renua, in yellow. If their true support is 2%, then their recent 1% poll was a 10% chance.
- The Green Party… in green. If their true support is 1%, then their recent 2% poll was an 8% chance.
- AAA-PBP, in brown. If their true support is 4%, then their recent 3% poll was an 18% chance.
- Social Democrats, in purple. If their true support is 6%, then their recent 4% poll was a 2% chance.
- Labour, in red. If their true support is 6%, then their recent 8% poll was a 3% chance.
Now be careful: all I am showing is the probability of polling at y, IF your true support is x.
It gives some comfort to those polling at low numbers: if your true support is 2%, then polling at 1% isn’t inconsistent.
For those who say that parties polling on 3% could be on zero this isn’t a correct interpretation. If your true support is 1% then the probability that you are polling as well as 3% is virtually nil and 2% is 8%.
What can be worrying is that if you believe your true support is say 7%, then the probability of two polls in a row putting you at 5% is 1/2500.
It is exceedingly easy to fall into a fallacy here and suggest the following:

Ten statistical gold stars to those who can explain some of the problems with this (there are at least two if not three big issues).
Whither the 3 & 5% Margins of Error? Why Confidence Intervals don’t work for small proportions.
Confidence Intervals
This isn’t the normal way of interpreting polls. The normal interpretation is that of a confidence interval. Let me explain how these are formed.
Consider a large population 
![\displaystyle [p-\Delta p,p+\Delta p]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bp-%5CDelta+p%2Cp%2B%5CDelta+p%5D&bg=ffffff&fg=545454&s=0&c=20201002)
into which 
![\displaystyle \mathbb{P}[p-\Delta p\leq \hat{p}\leq p+\Delta p]=R\%](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5Bp-%5CDelta+p%5Cleq+%5Chat%7Bp%7D%5Cleq+p%2B%5CDelta+p%5D%3DR%5C%25&bg=ffffff&fg=545454&s=0&c=20201002)
Another way of saying this is:
if the true proportion is
of
As an analogy, when Phil Taylor throws a dart at the bullseye, there is a certain percentage chance that he gets within 3 cm of the bullseye.
Now distance is symmetric: if you are sitting within 4 m of me then I am sitting within 4 m of you. Therefore, when we do a random sample, and there is an
![[\hat{p}-\Delta p,\hat{p}+\Delta p]](https://s0.wp.com/latex.php?latex=%5B%5Chat%7Bp%7D-%5CDelta+p%2C%5Chat%7Bp%7D%2B%5CDelta+p%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Such an interval is called a confidence interval.
The big problem is…
We try and get around this by saying… OK… what would 
I can quite easily reverse 
Using symmetry, therefore, when I do a random sample, 95.2% of the time I get that the distance from 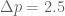
![[\hat{p}-2.5\%,\hat{p}+2.5\%]](https://s0.wp.com/latex.php?latex=%5B%5Chat%7Bp%7D-2.5%5C%25%2C%5Chat%7Bp%7D%2B2.5%5C%25%5D&bg=ffffff&fg=545454&s=0&c=20201002)
so when Sinn Fein poll at 20%, and I use this figure to approximate
The 3.2% MOE frequently quoted for Irish political polls, for a poll result of 20%, is translated into an
That is the poll is 99% confident that the true Sinn Fein vote is somewhere within 16.8% and 23.2%.
The same analysis for a 1% poll? How does the 3.2% margin of error apply? It simply doesn’t: you have a 1% margin of error (at 1%) with confidence 99.9% and a 0.5% margin of error (at 1%) with confidence 98.5%.
What about the magic 3% poll that could be zero? Not at all: under this assumption, the 95% margin of error is 1%.
The 95% margin of error at 3% is 1%.
Here are some 


Now there is a bit of a problem here… the smaller that
Sure we’e 99.9% sure that their true support is between 6.8% and 13.2%. Sure we ran the sums again and in fact we’d be 89.8% sure that the party are within 1.5% of 10%.
The problem is if the true support is say 9%, then a 1.5% MOE will increase the real
This shows that if your true support is better than the polls suggest, you are going to be given a smaller margin of error than you should be!
If your true support lags on 9% and you poll at 10% then prior to the polls the sample proportion will be in 7.5-10.5% with probability 91.4% but you will be given a confidence interval of 8.5-11.5% with 89.8% confidence. That is when you lag you are slightly less sure than you should be.
Similarly when your true support is ahead of polls on 11%, then prior to the polls the sample proportion will be in 9.5-12.5% with probability 88.3% but you will be given a confidence interval of 8.5-11.5% with 89.8% confidence. That is when you are doing better you are slightly more sure than you should be!
Perhaps this gave the Conservatives faux confidence: on polling figures of 33% they had more confidence at a 1.5% margin of error? Or are these differences to slight to notice…
Notice that the largest 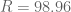
We are 99% confident that the true proportion is within the margin of error of the sample proportions.
That is one way that pollsters can do things… take as large a random sample as you can get. Tweak 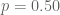
However this is not a good margin of error for all proportions: it is a worst possible case with an 
In fact, the margin of error — or rather the maximum margin of error — can actually be calculated even more roughly.
The Normal Approximation
When
In this approximation, the random variable
![\displaystyle N\left[np,\sqrt{\frac{p(1-p)}{n-1}}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+N%5Cleft%5Bnp%2C%5Csqrt%7B%5Cfrac%7Bp%281-p%29%7D%7Bn-1%7D%7D%5Cright%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Using properties of the normal distribution, we know that e.g. 95% of normal data is within 1.96 standard deviations of the mean. Translating all of this into the language of the last section that gives 95% confidence intervals for the true proportion
![\left[\hat{p}-1.96\sqrt{\frac{\hat{p}(1-\hat{p})}{n-1}},\hat{p}+1.96\sqrt{\frac{\hat{p}(1-\hat{p})}{n-1}}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Chat%7Bp%7D-1.96%5Csqrt%7B%5Cfrac%7B%5Chat%7Bp%7D%281-%5Chat%7Bp%7D%29%7D%7Bn-1%7D%7D%2C%5Chat%7Bp%7D%2B1.96%5Csqrt%7B%5Cfrac%7B%5Chat%7Bp%7D%281-%5Chat%7Bp%7D%29%7D%7Bn-1%7D%7D%5Cright%5D&bg=ffffff&fg=545454&s=0&c=20201002)
For example, a poll of 20% with 
This is what we should be using for margins of error for the larger proportions, bigger than about 7%:

A poll of 50% confers a margin of error of 3%… this is where our headline margin of errors are accurate.
Taking the approximation 
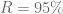
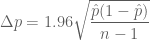

This is because the maximum of 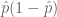
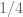
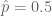


The problem is this approximation isn’t valid for small proportions, it is an overestimate for mid-ranking proportions and it is entirely inappropriate for small proportions.
If I can get my hands on a good machine in the next few days I will be happy to look at the exact situation — not even using the binomial approximation — for a constituency poll of say 


1 comment
Comments feed for this article
March 14, 2016 at 8:55 pm
J.P. McCarthy
Reblogged this on jpmccarthypolitics.