
You are currently browsing the category archive for the ‘Data Science’ category.
“Straight-Line-Graph-Through-The-Origin”
The words of Mr Michael Twomey, physics teacher, in Coláiste an Spioraid Naoimh, I can still hear them.
There were two main reasons to produce this straight-line-graph-through-the-origin:
- to measure some quantity (e.g. acceleration due to gravity, speed of sound, etc.)
- to demonstrate some law of nature (e.g. Newton’s Second Law, Ohm’s Law, etc.)
We were correct to draw this straight-line-graph-through-the origin for measurement, but not always, perhaps, in my opinion, for the demonstration of laws of nature.
The purpose of this piece is to explore this in detail.
Direct Proportion
Two variables 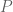
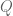


Correlation does not imply causation is a mantra of modern data science. It is probably worthwhile at this point to define the terms correlation, imply, and (harder) causation.
Correlation
For the purposes of this piece, it is sufficient to say that if we measure and record values of variables 


The variables
Causation
Causality is a deep philosophical notion, but, for the purposes of this piece, if there is a relationship between variables
In this case, we write 



Recent Comments