
You are currently browsing the category archive for the ‘Research’ category.
Abstract: Progress on the conjecture of Banica and Bichon that the classical permutation group is a maximal quantum subgroup of the quantum permutation group remains limited to a handful of small-parameter results. By Tannaka–Krein duality, any counterexample to this Maximality Conjecture must arise from a category strictly intermediate between the category 
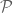

Unless I am being usually dumb, while the notion of a normal quantum subgroup is established in the theory of compact quantum groups, it’s something that rarely comes up. I am not entirely sure why this is.
I wondered if the classical permutation group 

Tracial central states on 
Let 
See Proposition 2.1 of Wang to see that if 




If a state 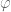



This is easy: both 


Recently, Freslon, Skalski & Wang have showed that the set of tracial central states is given by (Theorem 5.6):
![\displaystyle \mathrm{TCS}(S_N^+)=\{t\varepsilon+(1-t)h\colon t\in [0,1]\}\qquad (N\geq 6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BTCS%7D%28S_N%5E%2B%29%3D%5C%7Bt%5Cvarepsilon%2B%281-t%29h%5Ccolon+t%5Cin+%5B0%2C1%5D%5C%7D%5Cqquad+%28N%5Cgeq+6%29&bg=ffffff&fg=545454&s=0&c=20201002)
The Haar idempotent 





This also reproves that 

The Haar idempotent: it’s not central
So… there must exist a state 

EDIT: two years later, I considered instead this at the level of the Tannaka–Krein categories. If 








The following is an approach to the maximality conjecture for 
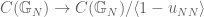
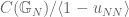
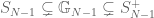
Most of my attempts at using this approach were doomed to fail as I explain below.
Let 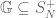
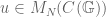
Definition 1 (Commutator and Isotropy Ideals)
Given 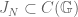
![\displaystyle J_N=\langle [u_{ij},u_{kl}]\,\mid\, 1\leq i,j,k,l\leq N\rangle.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J_N%3D%5Clangle+%5Bu_%7Bij%7D%2Cu_%7Bkl%7D%5D%5C%2C%5Cmid%5C%2C+1%5Cleq+i%2Cj%2Ck%2Cl%5Cleq+N%5Crangle.&bg=ffffff&fg=545454&s=0&c=20201002)
The isotropy ideal 

Lemma 1
The commutator ideal
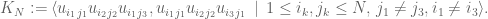
Proof:
with a similar statement for 
![\begin{aligned} [u_{i_2j_2},u_{i_3j_1}] & =u_{i_2j_2}u_{i_3j_1}-u_{i_3j_1}u_{i_2j_2} \\ \implies u_{i_1j_1}[u_{i_2j_2},u_{i_3j_1}] & = u_{i_1j_1}u_{i_2j_2}u_{i_3j_1}\qquad (i_1\neq i_3)\\ \implies u_{i_1j_1}u_{i_2j_2}u_{i_3j_1} & \in J_N, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Bu_%7Bi_2j_2%7D%2Cu_%7Bi_3j_1%7D%5D+%26+%3Du_%7Bi_2j_2%7Du_%7Bi_3j_1%7D-u_%7Bi_3j_1%7Du_%7Bi_2j_2%7D+%5C%5C+%5Cimplies+u_%7Bi_1j_1%7D%5Bu_%7Bi_2j_2%7D%2Cu_%7Bi_3j_1%7D%5D+%26+%3D+u_%7Bi_1j_1%7Du_%7Bi_2j_2%7Du_%7Bi_3j_1%7D%5Cqquad+%28i_1%5Cneq+i_3%29%5C%5C+%5Cimplies+u_%7Bi_1j_1%7Du_%7Bi_2j_2%7Du_%7Bi_3j_1%7D+%26+%5Cin+J_N%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=545454&s=0&c=20201002)
On the other hand:
![\begin{aligned} [u_{i_1j_1},u_{i_2j_2}] & =u_{i_1j_1}u_{i_2j_2}-u_{i_2j_2}u_{i_1j_1} \\ & =u_{i_1j_1}u_{i_2j_2}\sum_{k=1}^Nu_{i_1k}-\sum_{l=1}^{N}u_{i_1l}u_{i_2j_2}u_{i_1j_1} \\ & = u_{i_1j_1}u_{i_2j_2}u_{i_1j_1}+u_{i_1j_1}u_{i_2j_2}\sum_{k\neq j_1}u_{i_1j_1}u_{i_2j_2}u_{i_1k}-\\&u_{i_1j_1}u_{i_2j_2}u_{i_1j_1}\sum_{l\neq j_1}u_{i_1l}u_{i_2j_2}u_{i_1j_1}\\ \implies [u_{i_1j_1},u_{i_2j_2}]& \in K_N \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Bu_%7Bi_1j_1%7D%2Cu_%7Bi_2j_2%7D%5D+%26+%3Du_%7Bi_1j_1%7Du_%7Bi_2j_2%7D-u_%7Bi_2j_2%7Du_%7Bi_1j_1%7D+%5C%5C+%26+%3Du_%7Bi_1j_1%7Du_%7Bi_2j_2%7D%5Csum_%7Bk%3D1%7D%5ENu_%7Bi_1k%7D-%5Csum_%7Bl%3D1%7D%5E%7BN%7Du_%7Bi_1l%7Du_%7Bi_2j_2%7Du_%7Bi_1j_1%7D+%5C%5C+%26+%3D+u_%7Bi_1j_1%7Du_%7Bi_2j_2%7Du_%7Bi_1j_1%7D%2Bu_%7Bi_1j_1%7Du_%7Bi_2j_2%7D%5Csum_%7Bk%5Cneq+j_1%7Du_%7Bi_1j_1%7Du_%7Bi_2j_2%7Du_%7Bi_1k%7D-%5C%5C%26u_%7Bi_1j_1%7Du_%7Bi_2j_2%7Du_%7Bi_1j_1%7D%5Csum_%7Bl%5Cneq+j_1%7Du_%7Bi_1l%7Du_%7Bi_2j_2%7Du_%7Bi_1j_1%7D%5C%5C+%5Cimplies+%5Bu_%7Bi_1j_1%7D%2Cu_%7Bi_2j_2%7D%5D%26+%5Cin+K_N+%5Cend%7Baligned%7D&bg=ffffff&fg=545454&s=0&c=20201002)
Proposition 1
The commutator and isotropy ideals are Hopf*-ideals. The quotient 

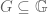
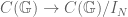

Via 
Theorem 1 (Wang/Banica/Bichon)

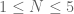
Consider the symmetric group 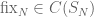
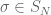
![X\sim \mathrm{Poi}[1]](https://s0.wp.com/latex.php?latex=X%5Csim+%5Cmathrm%7BPoi%7D%5B1%5D&bg=ffffff&fg=545454&s=0&c=20201002)

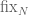

![\displaystyle \lim_{N\to \infty}\mathbb{P}[\mathrm{fix}_N(\xi_N)=m]=\mathbb{P}[X=m]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7BN%5Cto+%5Cinfty%7D%5Cmathbb%7BP%7D%5B%5Cmathrm%7Bfix%7D_N%28%5Cxi_N%29%3Dm%5D%3D%5Cmathbb%7BP%7D%5BX%3Dm%5D&bg=ffffff&fg=545454&s=0&c=20201002)
In this note we will look at the distribution in the case where the uniform distribution is conditioned on 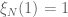
Theorem
Let ![1+\mathrm{Poi}[1]](https://s0.wp.com/latex.php?latex=1%2B%5Cmathrm%7BPoi%7D%5B1%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![\displaystyle \lim_{N\to \infty}\mathbb{P}[\mathrm{fix}_N(\xi_N)=m]=\mathbb{P}[X=m-1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7BN%5Cto+%5Cinfty%7D%5Cmathbb%7BP%7D%5B%5Cmathrm%7Bfix%7D_N%28%5Cxi_N%29%3Dm%5D%3D%5Cmathbb%7BP%7D%5BX%3Dm-1%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Proof: What can be shown, ostensibly from stuff from the quantum permutation side of the house is that, where 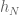

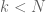

the 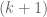
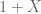
![\displaystyle \sum_{t=0}^\infty t^k\mathbb{P}[1+X=t]=\sum_{t=0}^\infty t^k\mathbb{P}[X=t-1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D0%7D%5E%5Cinfty+t%5Ek%5Cmathbb%7BP%7D%5B1%2BX%3Dt%5D%3D%5Csum_%7Bt%3D0%7D%5E%5Cinfty+t%5Ek%5Cmathbb%7BP%7D%5BX%3Dt-1%5D&bg=ffffff&fg=545454&s=0&c=20201002)




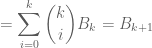
using the fact that the Bell numbers are the moments of that Poisson distribution and the standard recurrence for the Bell numbers.
Local vs Global Conditioning of Quantum Permutations
In the quantum case we define
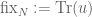
where 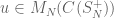


Note that when we measure the Haar state with some finite spectrum version of
- the probability of finding an integer number of fixed points is zero, and
- independently of
In the classical case above when we chose the permutation uniformly from those who fix one, there are two ways of viewing it:
- we pick an element of
- we consider the isotropy subgroup
and choose our permutation from
.
Classically, these are the same thing. In the quantum case these two things can be interpreted differently. The second case is quite clear in the quantum case. For 
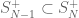
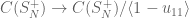
The analogue of the uniform distribution on 



I guess this is marginally more interesting than the unshifted version.
Now, what about an analogue of “we pick an element of 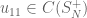

And, it turns out, as above, using stuff from the quantum permutation side of the house:
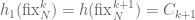
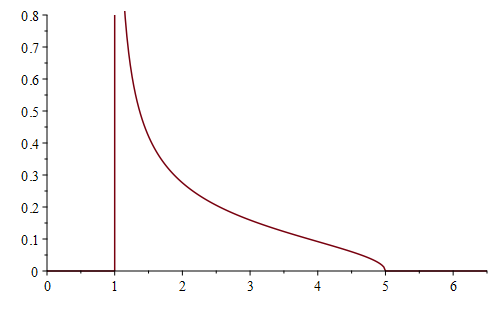
Quite quickly from here we find that the density of the distribution of 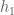
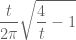
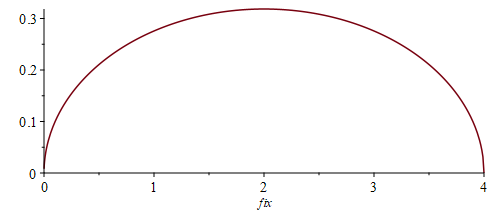
This is so interesting:
- it doesn’t change the support — we still find between 0 and 4 fixed points,
- we have a new symmetry about
, we had another unexpected symmetry here.
- the mean jumps from one to two, that is not unexpected, but
- the mode jumps from zero to two!
- even though we have observed one to one, there can still be less than one fixed point when we measure… and this happens with probability
.
The next obvious question is what happens with:

Epilogue?
So what about this local vs global conditioning? Well, no matter what subsequent measurements are made to
This is not the case with
Classical Warm-up
Let 

This algebra is commutative, but we will use some non-commutative algebraic analogues. Let 

When choosing a permutation at random what is the probability that it sends 
![\displaystyle \mathbb{P}[\pi(1)=1]=\pi(\mathbf{1}_{1\to 1})=\frac{1}{N}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%5Cpi%281%29%3D1%5D%3D%5Cpi%28%5Cmathbf%7B1%7D_%7B1%5Cto+1%7D%29%3D%5Cfrac%7B1%7D%7BN%7D&bg=ffffff&fg=545454&s=0&c=20201002)
Once this has been observed, there is a conditioning of the state 

The state was given by 
Consider a subset 

This is an observable, which basically asks of a permutation, do you map three into 
What is the probability that a random permutation maps three into
We find, with a fairly elementary calculation that the answer to this question is:
![\displaystyle \mathbb{P}[\pi_{1\to 1}(3)\in S]=\frac{|S|}{N-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%5Cpi_%7B1%5Cto+1%7D%283%29%5Cin+S%5D%3D%5Cfrac%7B%7CS%7C%7D%7BN-1%7D&bg=ffffff&fg=545454&s=0&c=20201002)
If 


What is the probability that after seeing 

![\displaystyle \mathbb{P}[\nu(2)=2]=\frac{1}{N-2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%5Cnu%282%29%3D2%5D%3D%5Cfrac%7B1%7D%7BN-2%7D&bg=ffffff&fg=545454&s=0&c=20201002)
Therefore, where 
![\displaystyle \mathbb{P}[(\pi(2)=2)\succ (\pi(3)\in S)\succ(\pi(1)=1)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%28%5Cpi%282%29%3D2%29%5Csucc+%28%5Cpi%283%29%5Cin+S%29%5Csucc%28%5Cpi%281%29%3D1%29%5D&bg=ffffff&fg=545454&s=0&c=20201002)

Now let us ask a ridiculous question. What was the probability that 
![\displaystyle \mathbb{P}[\pi_{1\to 1}(1)=1]=\dfrac{\pi(\mathbf{1}_{1\to 1}\mathbf{1}_{1\to 1}\mathbf{1}_{1\to 1})}{\pi(\mathbf{1}_{1\to 1})}=1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%5Cpi_%7B1%5Cto+1%7D%281%29%3D1%5D%3D%5Cdfrac%7B%5Cpi%28%5Cmathbf%7B1%7D_%7B1%5Cto+1%7D%5Cmathbf%7B1%7D_%7B1%5Cto+1%7D%5Cmathbf%7B1%7D_%7B1%5Cto+1%7D%29%7D%7B%5Cpi%28%5Cmathbf%7B1%7D_%7B1%5Cto+1%7D%29%7D%3D1&bg=ffffff&fg=545454&s=0&c=20201002)
Of course the answer is zero. Can we actually see it in the above framework: well, yes, because the algebra of functions is commutative. You end up with evaluating a state at

but commutativity sees 

We don’t have to do state conditioning and multiplication to calculate the probability that a random permutation maps one to one, then maps three into 

Let us remark that this probability is increasing in 

Let’s Go Quantum
In the case of quantum permutations, so talking 

![\displaystyle \mathbb{P}[(h(1)=2)\succ(h(3)=3)\succ (h(1=1))]=\frac{N-3}{q(N)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%28h%281%29%3D2%29%5Csucc%28h%283%29%3D3%29%5Csucc+%28h%281%3D1%29%29%5D%3D%5Cfrac%7BN-3%7D%7Bq%28N%29%7D&bg=ffffff&fg=545454&s=0&c=20201002)
Anyway, the quantum versions of the 

![\mathbb{P}[(h(2)=2)\succ (h(3)\in S)\succ (h(1)=1)]:=h(|u_{22}u_{S,3}u_{11}|^2)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%5B%28h%282%29%3D2%29%5Csucc+%28h%283%29%5Cin+S%29%5Csucc+%28h%281%29%3D1%29%5D%3A%3Dh%28%7Cu_%7B22%7Du_%7BS%2C3%7Du_%7B11%7D%7C%5E2%29&bg=ffffff&fg=545454&s=0&c=20201002)
where 
![\displaystyle \mathbb{P}[(h(2)=2)\succ (h(3)\in S)\succ (h(1)=1)]=\frac{|S|(N^2-5N+5+|S|)}{(N-2)q(N)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%28h%282%29%3D2%29%5Csucc+%28h%283%29%5Cin+S%29%5Csucc+%28h%281%29%3D1%29%5D%3D%5Cfrac%7B%7CS%7C%28N%5E2-5N%2B5%2B%7CS%7C%29%7D%7B%28N-2%29q%28N%29%7D&bg=ffffff&fg=545454&s=0&c=20201002)
This is also increasing in 
This quantity is related to the classical probability above, and there are asymptotic similarities. Writing 


![\displaystyle \mathbb{P}[(h(2)=2)\succ (h(3)\in S)\succ (h(1)=1)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%28h%282%29%3D2%29%5Csucc+%28h%283%29%5Cin+S%29%5Csucc+%28h%281%29%3D1%29%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![\displaystyle=\mathbb{P}[(\pi(2)=2)\succ (\pi(3)\in S)\succ(\pi(1)=1)]\cdot\left[1-\frac{|S^c|+1}{q(N)}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%3D%5Cmathbb%7BP%7D%5B%28%5Cpi%282%29%3D2%29%5Csucc+%28%5Cpi%283%29%5Cin+S%29%5Csucc%28%5Cpi%281%29%3D1%29%5D%5Ccdot%5Cleft%5B1-%5Cfrac%7B%7CS%5Ec%7C%2B1%7D%7Bq%28N%29%7D%5Cright%5D&bg=ffffff&fg=545454&s=0&c=20201002)
I guess this also says, the larger
A twist
What if instead of looking at 



From our classical intuition, we would probably just expect, well, the same really. The larger the value of 


![\displaystyle \mathbb{P}[(h(1)=2)\succ (h(3)\in S)\succ (h(1)=1)]=\dfrac{|S|(N-2-|S|)}{q(N)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%28h%281%29%3D2%29%5Csucc+%28h%283%29%5Cin+S%29%5Csucc+%28h%281%29%3D1%29%5D%3D%5Cdfrac%7B%7CS%7C%28N-2-%7CS%7C%29%7D%7Bq%28N%29%7D&bg=ffffff&fg=545454&s=0&c=20201002)
Proof: Consider 


Like in the classical case, by definition here, 

Now, classically, this is just a sum of zero terms equal to zero, but not in the quantum world where we have these 

Now take the 

This yields the strange probability above. I think any intuition I have for this would be very much post-hoc. I think I will just let it hang there as something weird, cool and mysterious about quantum permutations…
This paper referenced in the title (preprint here) tries to establish some very basic properties of a so-called exotic quantum permutation group, one intermediate to the classical and quantum permutation groups:

If a compact matrix quantum subgroup 




then in fact 
The paper above fails at generators of length four though. The invariances do not determine the Haar measure on
However, a very basic algebraic result, that a product of three generators in exotic

but this is not the case, as 

Idea and Intuition
Let 




It has the following universal property. Suppose 







If the 
My (highly non-rigourous, the tilde reminding of hand-waving) intuition for this object is that you collect all (really all, not just isomorphism classes, we want below ![C([0,1])](https://s0.wp.com/latex.php?latex=C%28%5B0%2C1%5D%29&bg=ffffff&fg=545454&s=0&c=20201002)
![C([0,2]](https://s0.wp.com/latex.php?latex=C%28%5B0%2C2%5D&bg=ffffff&fg=545454&s=0&c=20201002)



Then the *-homomorphism 

This intuition works well but we should give a brief account of things are done properly.
First off, not every relation will give a universal 





The first approach to show that 

![A_\alpha=C([0,\alpha])](https://s0.wp.com/latex.php?latex=A_%5Calpha%3DC%28%5B0%2C%5Calpha%5D%29&bg=ffffff&fg=545454&s=0&c=20201002)




which is unbounded. The relations must give a bounded norm to the generators.
As an example of relations that do bound the generators, consider,

These relations bounds the norm of the generators 

Note here the relations are given by polynomial relations. If the polynomial relations are suitably admissible (i.e. give a bound to the generators), in this setting there is a real construction (real vs our ridiculous 

In fact, this is only a small class of the possible relations. I suggest there are at least two more types:
, a non-polynomial relation, to the polynomial relation
gives an admissible set of relations, and
. For
- (admissible) strong relations (see here for a use of this, with reference)
The constructions in one or both of cases might be constructive, as in the case (admissible) polynomial relations, but there is also an approach using category theory. But the main feature in all such definitions is the universal property, whose use could be summarised as follows:
Let
- is some polynomial
in the generators non-zero,
- is
- is
because, if
. So, for example, where
is some such
- if
, then
as
,
- if
- if the commutator
, so that
These quotients
![\pi([g_i,g_j])=[f_i,f_j]](https://s0.wp.com/latex.php?latex=%5Cpi%28%5Bg_i%2Cg_j%5D%29%3D%5Bf_i%2Cf_j%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Two Examples
A projection 


Existence is easy, because the norm of a non-zero projection is one. To answer questions about this algebra consider the infinite dihedral group 





A partition of unity is a finite set of projections that sum to the identity, 


Consider the following magic unitary:

Note that the 



It is possible to show using a magic unitary with entries in 

In addition it can be shown that for 




is a magic unitary, and thus by the universal property 
Commutative Examples
If a universal ![[g_i,g_j]=0](https://s0.wp.com/latex.php?latex=%5Bg_i%2Cg_j%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002)



Theorem
If 

Proof: Characters are *-homomorphisms 
Suppose that 

On the contrary, suppose that
Examples
For 

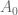
For 
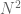
For

you end up with tuples of ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)

Liberations
An interesting business here is to start with a universal commutative 

Liberating the second example above from commutativity is the passage from the permutation group 
We can also, of course, work in the other direction, imposing commutativity on not-necessarily universal 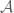

Imposing commutativity is not so scary: using the above you just get 

This can be used: for example if a quantum group acts on a structure
- If you have positive elements
in a
then we can bound the summands
. Write
. Note
. Let
and apply this to
which yields, with
. The result follows by positivity of the sum and the state. To apply to the above play with the
. Then let
and define a state
on
, also equal to the norm of
I am or rather was interested in the following problem: while we cannot hope to measure with infinite precision in the real world, in the mathematical world can I measure a continuous-spectrum self-adjoint operator given a fixed state? That is measure it with infinite precision?
Let 


Note that 






Let 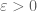

Suppose for a state 
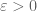

(the situation where 
Then we want to consider the entity:

If this limit exists then it is a state.
Alas, this limit does not exist in general. There is a commutative counterexample by Nik Weaver on MO, which we will share here.
Let ![A=L^{\infty}([0,1])](https://s0.wp.com/latex.php?latex=A%3DL%5E%7B%5Cinfty%7D%28%5B0%2C1%5D%29&bg=ffffff&fg=545454&s=0&c=20201002)


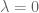

Define
![\displaystyle S=\bigcup_{n=0}^{\infty} [10^{-(2n+1)},10^{-2n}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%3D%5Cbigcup_%7Bn%3D0%7D%5E%7B%5Cinfty%7D+%5B10%5E%7B-%282n%2B1%29%7D%2C10%5E%7B-2n%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002)
and 
![L^{\infty}([0,1])](https://s0.wp.com/latex.php?latex=L%5E%7B%5Cinfty%7D%28%5B0%2C1%5D%29&bg=ffffff&fg=545454&s=0&c=20201002)
Consider 



However, at 


Now, without proof we could expect that for ![A=C([0,1])](https://s0.wp.com/latex.php?latex=A%3DC%28%5B0%2C1%5D%29&bg=ffffff&fg=545454&s=0&c=20201002)

The problem here is that for 
![g\in L^\infty([0,1])](https://s0.wp.com/latex.php?latex=g%5Cin+L%5E%5Cinfty%28%5B0%2C1%5D%29&bg=ffffff&fg=545454&s=0&c=20201002)
The best we can do is measure 


In the commutative case, this is giving the average of 

I had hoped to use 

Perhaps we could try and understand in which
…and why it doesn’t work for a quantum alternating group
Despite problems around its existence being well-known, the Google search “quantum alternating group” only gets one (relevant) hit. This is to a paper of Freslon, Teyssier, and Wang, which states:
We therefore have to resort to another idea, which is to compare the process with the so-called pure quantum transposition random walk and prove that they asymptotically coincide. This is a specifically quantum phenomenon connected to the fact that the pure quantum transposition walk has no periodicity issue because there is no quantum alternating group.
Let us explain this a little. Take a deck of 
![\displaystyle \lim_{k\to\infty}\mathbb{P}[\xi_k=\sigma]=\frac{1}{N!}\qquad(\sigma\in S_{N})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7Bk%5Cto%5Cinfty%7D%5Cmathbb%7BP%7D%5B%5Cxi_k%3D%5Csigma%5D%3D%5Cfrac%7B1%7D%7BN%21%7D%5Cqquad%28%5Csigma%5Cin+S_%7BN%7D%29&bg=ffffff&fg=545454&s=0&c=20201002)
The random variable 

Take a permutation
![\displaystyle \lim_{k\to\infty}\mathbb{P}[\xi_{2k}=\sigma]=0,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7Bk%5Cto%5Cinfty%7D%5Cmathbb%7BP%7D%5B%5Cxi_%7B2k%7D%3D%5Csigma%5D%3D0%2C&bg=ffffff&fg=545454&s=0&c=20201002)
and so this pure random transposition shuffle cannot mix up the deck of cards. The order of the deck alternates (geddit) between 

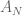
Amaury Freslon instigated a study of a quantum version of the above random walk. The probability distribution of the shuffles above is:

The measure 



If ![u^c=[\mathbf{1}_{j\to i}]_{i,n=1,...,N}](https://s0.wp.com/latex.php?latex=u%5Ec%3D%5B%5Cmathbf%7B1%7D_%7Bj%5Cto+i%7D%5D_%7Bi%2Cn%3D1%2C...%2CN%7D&bg=ffffff&fg=545454&s=0&c=20201002)




Freslon’s 
If you shuffle according to classical 

The classical alternating group is:

but with no quantum sign, we don’t seem to be able to define a quantum alternating group in the same way.
This is related to difficulties around the determinant (equal to the sign for permutation matrices). I think, but would have to check, that we can quotient 

Private communication has shown me a proof that if you quotient any compact matrix quantum group with 

and not something non-commutative, corresponding to a quantum alternating group 
Another way?
This no-go result, which is cool but unpublished, doesn’t rule out a quantum alternating group of the form:

There is indeed for every 

Given a quantum permutation group 

I have a particular interest in characters, and have a pre-print (Section 4) doing some analysis on them. Let 


In this case we write 



The characters have support projections, and these in general do not live in 

(as an aside, if we transpose in 



It turns out that the support projection 





Enter this talk by Gilles Gonçalves De Castro (Universidade Federal de Santa Catarina, Brazil), who teaches us with his coauthor Giulioano Boava that it is possible to include (admissible) strong as well as norm relations in defining a universal
An idea!
So, why not take 


There is a lot of work to do here to prove that this is a quantum group… have we a *-homomorphism 
Failure
Actually we don’t. In fact, either the algebra does not admit a quantum group structure OR

Unfortunately, because of non-coamenability issues, lots of algebras of continuous functions on quantum permutation groups also have 

In particular, the reduced algebra of functions 

Then with the help of J. De Ro, this means we have a Hopf*-algebra morphism on the level of the dense Hopf*-algebras, saying that 
This isn’t a great no-go theorem: but a log of something that doesn’t work. And of course this approach doesn’t work for any subgroup of
Alice, Bob and Carol are hanging around, messing with playing cards.
Alice and Bob each have a new deck of cards, and Alice, Bob, and Carol all know what order the decks are in.
Carol has to go away for a few hours.
Alice starts shuffling the deck of cards with the following weird shuffle: she selects two (different) cards at random, and swaps them. She does this for hours, doing it hundreds and hundreds of times.
Bob does the same with his deck.
Carol comes back and asked “have you mixed up those decks yet?” A deck of cards is “mixed up” if each possible order is approximately equally likely:
![\displaystyle \mathbb{P}[\text{ deck in order }\sigma\in S_{52}]\approx \frac{1}{52!}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%5B%5Ctext%7B+deck+in+order+%7D%5Csigma%5Cin+S_%7B52%7D%5D%5Capprox+%5Cfrac%7B1%7D%7B52%21%7D&bg=ffffff&fg=545454&s=0&c=20201002)
She asks Alice how many times she shuffled the deck. Alice says she doesn’t know, but it was hundreds, nay thousands of times. Carol says, great, your deck is mixed up!
Bob pipes up and says “I don’t know how many times I shuffled either. But I am fairly sure it was over a thousand”. Carol was just about to say, great job mixing up the deck, when Bob interjects “I do know that I did an even number of shuffles though.“.
Why does this mean that Bob’s deck isn’t mixed up?

Recent Comments