An essence of mathematics is to cut through the gloss of each topic and exhibit the core features of the construct.
We all encountered vectors as a teenager. We may have been told that a vector is a physical quantity with magnitude in direction. This is to distinguish it from a scalar – which has magnitude alone. It begs the question – what has direction without magnitude? Anyway we can think of those familiar arrow vectors in the plane, think of all possible magnitudes and directions, and think of them as some big, infinite set  . One basic thing about these vectors is that we can add them together – by the parallelogram law and more than that when we add them together we get another vector. So there is a way to add vectors
. One basic thing about these vectors is that we can add them together – by the parallelogram law and more than that when we add them together we get another vector. So there is a way to add vectors  ,
,  together, and also
together, and also  . This means
. This means 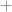 is a closed binary relation. Furthermore it is doesn’t matter in what order we add the vectors:
is a closed binary relation. Furthermore it is doesn’t matter in what order we add the vectors:  , the addition is commutative. Also we can take a vector and double it, or treble it or indeed multiply it by any real number
, the addition is commutative. Also we can take a vector and double it, or treble it or indeed multiply it by any real number  – and again we’ll get another vector
– and again we’ll get another vector  (with
(with 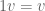 ). We don’t care about multiplying two vectors – at the moment. There is special zero vector,
). We don’t care about multiplying two vectors – at the moment. There is special zero vector,  , such that for any vector ,
, such that for any vector ,  . Every vector has a negative, namely
. Every vector has a negative, namely 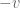 , such that
, such that 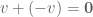 . Also the addition and scalar multiplication satisfies some nice algebraic laws; those of associativity and distributivity.
. Also the addition and scalar multiplication satisfies some nice algebraic laws; those of associativity and distributivity.
Vector Spaces
So we note a set of vectors, a field 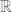 of scalars, a vector addition and a scalar multiplication
of scalars, a vector addition and a scalar multiplication  . The following axioms are satisfied
. The following axioms are satisfied 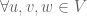 ,
, 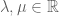 .
.
- ,
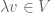 (Closure)
(Closure)
 such that
such that 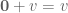 (zero vector)
(zero vector) such that (negative vectors)
such that (negative vectors)- (commutativity)
- (multiplicative identity)
 (associativity)
(associativity) ,
,  , and
, and  (distributivity)
(distributivity)
Now the structure can be abstracted and we say that any (set,field,addition,scalar multiplication) tuple  which satisfies these axioms is called a vector space.
which satisfies these axioms is called a vector space.
Bases
One of the features of the geometric vectors seen in second level education is that they can be written in the  –
–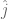 basis. In the context of how MA 2055 is presently taught (2009/10), and are said to be basis because every vector has a unique representation in terms of a linear combination of and :
basis. In the context of how MA 2055 is presently taught (2009/10), and are said to be basis because every vector has a unique representation in terms of a linear combination of and : 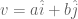 uniquely. Again this notion of a basis may be abstracted. A set
uniquely. Again this notion of a basis may be abstracted. A set  is said to be a basis of if every vector
is said to be a basis of if every vector 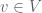 has a unique representation as
has a unique representation as

It can be shown that this condition is equivalent to the basis being a linearly independent, spanning set. In MA 2055, a set  is said to be linearly independent if the only linear combination of the
is said to be linearly independent if the only linear combination of the  is the trivial one; i.e. linear independence is
is the trivial one; i.e. linear independence is

In turn this is equivalent to the condition that none of the vectors are a linear combination of the others – in some sense the ‘directions’ of the vectors are all different. A spanning set is one in which all possible linear combinations exhaust the space:

i.e. a set  is a spanning set for if span
is a spanning set for if span  . The dimension of a vector space is given by the number of vectors in a basis.
. The dimension of a vector space is given by the number of vectors in a basis.
Linear Maps
One of the first things to do when an abstract structure is defined is to consider functions between them. A linear map is a function between two vector spaces that preserves the operations of vector addition and scalar multiplication. In other words a linear map is any function  where
where 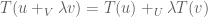 for any vectors
for any vectors  and scalar
and scalar  . The quick calculation:
. The quick calculation:

shows that a linear map is defined what it does to the basis vectors. Let 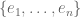 and
and  be bases for
be bases for  and . If the linear map is defined by the equations:
and . If the linear map is defined by the equations:

then the matrix with columns  acts on the vectors
acts on the vectors 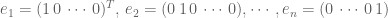 according to
according to  . Hence, once a basis is fixed, a linear map is nothing but a matrix (and indeed a matrix is suitably linear).
. Hence, once a basis is fixed, a linear map is nothing but a matrix (and indeed a matrix is suitably linear).
Occasionally a linear map will be invertible. There are many equivalent definitions of invertible the most intuitive being that is bijective. A function  is bijective if:
is bijective if:
-
If
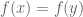
, then
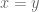
-
For all

, there exists

such that

.
Now suppose a linear map sends two distinct vectors 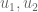 to a vector ; i.e
to a vector ; i.e 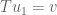 and
and  . Thence
. Thence

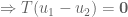
That is, a non-zero vector, 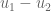 is sent to . By linearity, any linear map will send to . Hence a linear map cannot be invertible if
is sent to . By linearity, any linear map will send to . Hence a linear map cannot be invertible if 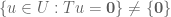 . By linearity this is an equivalent condition to invertibility: a linear map is invertible if and only if
. By linearity this is an equivalent condition to invertibility: a linear map is invertible if and only if  .
.
A few dimensional considerations show that to be invertible a linear map must map between vector spaces of equal dimension. In particular, when bases are set, the matrix of the linear map will be a square matrix. In the following assume the dimension of the spaces is  .
.
Given a matrix , to calculate the inverse of , 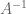 , a quantity known as the determinant of ,
, a quantity known as the determinant of ,  is calculated. The subsequent analysis yields another equivalent condition for invertibility: a linear map is invertible if and only if
is calculated. The subsequent analysis yields another equivalent condition for invertibility: a linear map is invertible if and only if 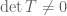 .
.
The Eigenvalue Problem
For some vectors the action of a linear map is by scalar multiplication:
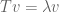
In this case is called an eigenvector of the linear map with eigenvalue  . In the first instance we restrict to non-zero vectors. Otherwise every number is an eigenvalue of every linear map because
. In the first instance we restrict to non-zero vectors. Otherwise every number is an eigenvalue of every linear map because  for all
for all  . Hence restrict to non-zero vectors and hopefully it will make sense to consider the eigenvalues of a linear map . Consider
. Hence restrict to non-zero vectors and hopefully it will make sense to consider the eigenvalues of a linear map . Consider


Now if  is invertible then both sides may be hit by
is invertible then both sides may be hit by  to yield
to yield 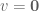 which is not allowed. Hence must not be invertible and thus the eigenvalues of are given by the () solutions of the (polynomial) equation:
which is not allowed. Hence must not be invertible and thus the eigenvalues of are given by the () solutions of the (polynomial) equation:

Indeed this gives yet another equivalent condition to being invertible: a linear map is invertible if and only if 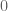 is not an eigenvalue.
is not an eigenvalue.
A particularly nice class of linear maps are diagonaliseable linear maps. Suppose a set of eigenvectors  with eigenvalues
with eigenvalues  of a linear map form a basis. Thence in this basis, is a diagonal matrix with the
of a linear map form a basis. Thence in this basis, is a diagonal matrix with the 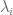 along the diagonal.
along the diagonal.
Inner Product Spaces
Earlier on we mentioned that we don’t care about multiplying vectors however there is the notion of a dot product of two vectors. For every pair of vectors, 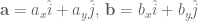 on the – plane, there is a scalar,
on the – plane, there is a scalar,  , called the dot product of
, called the dot product of 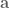 and
and 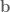 :
:

The dot product satisfies the following two properties for all vectors 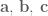 and scalars
and scalars  :
:
-
The dot product is linear on the left:

.
-
The dot product is positive definite:
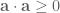
, with equality if and only if

.
In a similar modus operandi to before, this structure can be abstracted to a more general map from pairs of vectors to  . Any map
. Any map  that satisfies 1. and 2. for all vectors
that satisfies 1. and 2. for all vectors  and scalar
and scalar  , with the additional property that
, with the additional property that  is conjugate linear on the right (
is conjugate linear on the right ( ), is an inner product on and
), is an inner product on and  is an inner product space.
is an inner product space.
With respect to a given inner product, to each linear map  there exists its adjoint,
there exists its adjoint, 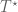 , given by:
, given by:

A linear map is called self-adjoint if  .
.
Proposition 1: The eigenvalues of a self-adjoint linear map are real.
Proof: Let be eigenvectors of eigenvalues of the linear map . Now

Similarly,

But is self-adjoint thence  and because eigenvectors are non-zero and positive definiteness
and because eigenvectors are non-zero and positive definiteness 

The spectral theorem for self-adjoint maps states that a self-adjoint map has a basis of eigenvectors. When a basis is fixed, it may be seen that the matrix of a self-adjoint linear map is one that is equal to its conjugate-transpose:  . These two facts combine to give a basis-dependent proof of Proposition 1.
. These two facts combine to give a basis-dependent proof of Proposition 1.
Proof (basis-dependent): By the spectral theorem, has an eigenbasis, say . Let be the matrix representation of in this basis. is thus the diagonal matrix with  along the diagonal. Now
along the diagonal. Now  . As is diagonal it is equal to its transpose. Taking conjugates shows
. As is diagonal it is equal to its transpose. Taking conjugates shows
Vector Space Isomorphism
Sometimes two different vector spaces appear to behave very similarly even if outwardly they look very different. For example, the set of polynomials of degree at most two with real coefficients behaves exactly like  when we add vectors together, etc. Indeed as vector spaces they have identical structure. To show they are isomorphic we must construct a bijective homomorphism (isomorphism) between them. If the isomorphism is linear then the homomorphism property will be respected. So now we can say that two vector spaces and are isomorphic as vector spaces if there exists a bijective linear map from
when we add vectors together, etc. Indeed as vector spaces they have identical structure. To show they are isomorphic we must construct a bijective homomorphism (isomorphism) between them. If the isomorphism is linear then the homomorphism property will be respected. So now we can say that two vector spaces and are isomorphic as vector spaces if there exists a bijective linear map from  . For example,
. For example, 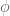 defined by
defined by 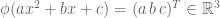 is a bijective linear map.
is a bijective linear map.
Subspaces
A vector subspace is a subset of a vector space that is a vector space in its own right. That is the axioms of a vector space are satisfied by . Now axioms 5., 6. and 7. hold automatically as is in a vector space. Suppose
-
-
For all
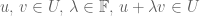
Then axiom 1. holds by letting 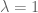 and
and  . Axiom 2. is vacuously true. Axiom 3. holds by letting and
. Axiom 2. is vacuously true. Axiom 3. holds by letting and 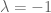 . Conditions 1. & 2. here comprise the Subspace Test.
. Conditions 1. & 2. here comprise the Subspace Test.


1 comment
Comments feed for this article
September 29, 2017 at 7:47 am
Why Do We Multiply Matrices Like We Do? | J.P. McCarthy: Math Page
[…] This note will only look at matrices but it should be clear, particularly by looking at this note, how this generalises to matrices of arbitrary […]